At Monitorama 2018, I shared some of the cool process and knowledge I’ve learned from developing a product for people other than myself to consume. After spending six years on call, I now build software that wakes people up in the night — AKA, infrastructure and tooling for systems monitoring and performance analysis. As someone who’s been there, I’m conscientious about building quality software that people delight in using. Even if that software’s job is to wake them up, at the very least that can be for a good reason.
In this post, I’ll recap that talk, sharing the motivations behind building open source software, our approach to testing, and the critical role community plays in building better software.
Motivations for building open source software
First, a definition: open source is code that is publicly available, with permission to use, modify, and share. I’d also extend that to include a license; anyone can put code out in public, but in order to be able to use it you need to be able to tell people how they can use it, contribute to it, and where to find it.
What motivates people to work on open source software? For many, it’s the fact that much of our daily work relies on it. Even the tools we pay for are built on open source technology. Personally, I’m also motivated by the desire to build and maintain tools that make people’s jobs easier. As an on-call veteran, I don’t want to needlessly wake someone up in the middle of the night because I didn’t write something properly. Finally, there is something very rewarding about seeing your code run in an infrastructure you don’t control — to see that others are using (and benefitting from) the tools you created.
Testing OSS: making sure code is performant
Building open source software is all well and good, but it’s also important to make sure it’s working as it should. We released (and open sourced) Sensu 2.0 as an Alpha earlier this year; we rewrote our product in Go on top of etcd. While we still use a pub/sub model, it’s now embedded on top of etcd. You run just one binary, and it’s faster to set up and start using, as compared to v1. Our Alpha was far from polished or perfect, but we wanted to get it in the hands of our users to hear about pain points, what people were missing, and what they liked.
Once we had an Alpha — and some information from our users — we started planning what QA testing would look like. Since we’re not the primary consumers of our software — and we don’t run it on internal infrastructure — it’s tricky knowing whether our software is working. Our tests during development were limited to unit, integration, and end-to-end testing, which have their own challenges and tend to be brittle in some instances (more on this later). These were useful for determining whether code was working during development, but — because we weren’t testing in real-world environments — they weren’t useful in determining feature need, usability, or system behavior. We weren’t testing in a real-world environment. Usability testing is also tough when you’re not a core user of your product, especially with such a malleable framework. With so much flexibility in our system, we weren’t going to be able to test every possibility.
When testing software, we want to keep the following questions in mind:
- Does the software behave as we expect?
- Does it solve a problem or need?
- Can we find the bugs before users do?
In order to answer those questions, we needed to do different types of testing to benchmark how our system was performing:
- Code quality. We used Code Climate’s Velocity to track PR size, time to merge, and complexity risk, as well as alert us on the size of PRs. Our PR goal was 200 lines of code, which we achieved about 50% of the time. But, compare that to this time last year and it’s a completely different story.
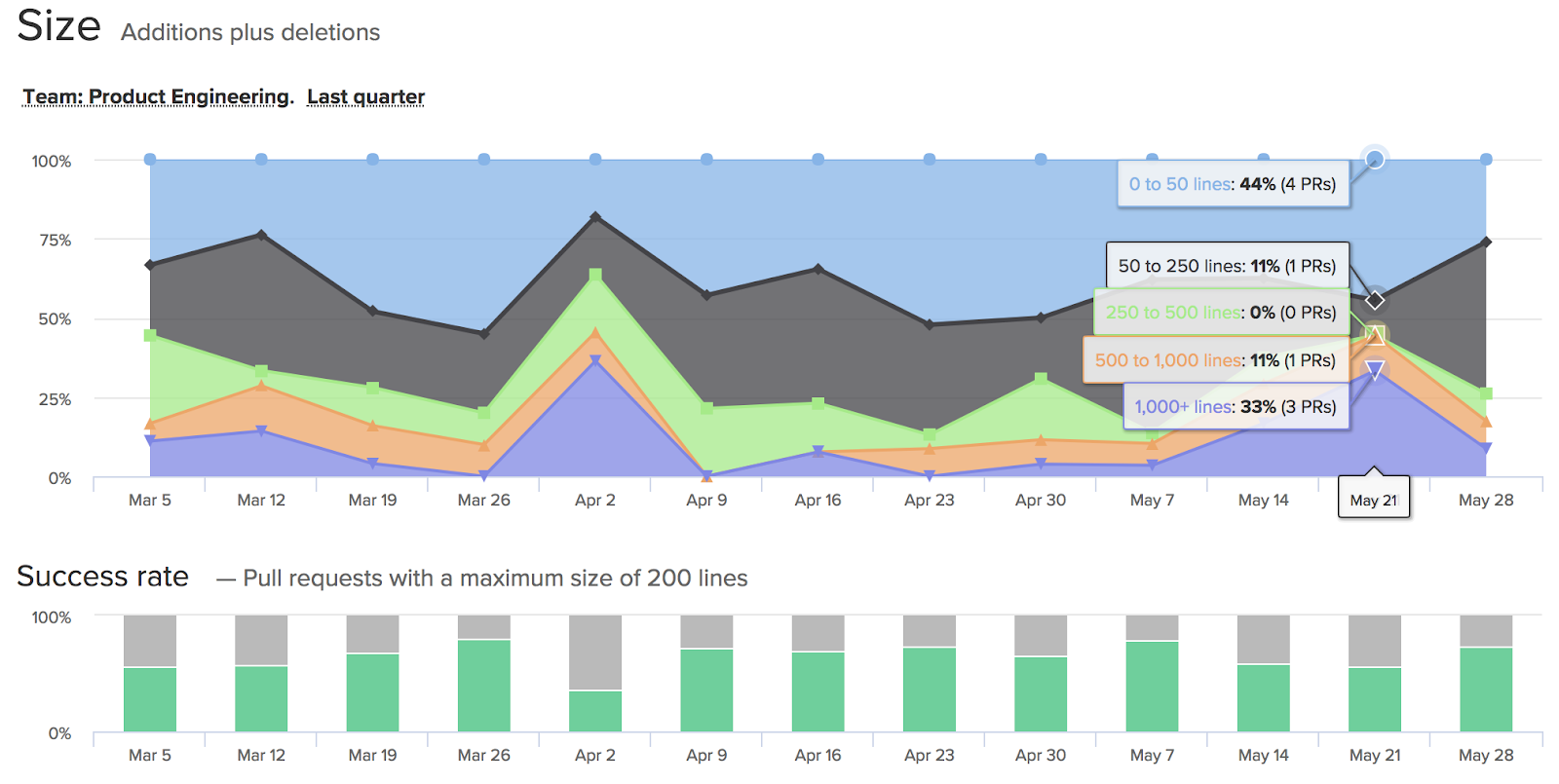 Source: Velocity by Code Climate
Source: Velocity by Code Climate
Although this is a neat metric, it’s not end all be all; it can’t determine whether your codebase is keeping up with consistent quality because features and bug cycles are changing over time.
- Code analysis, or our build success ratio.
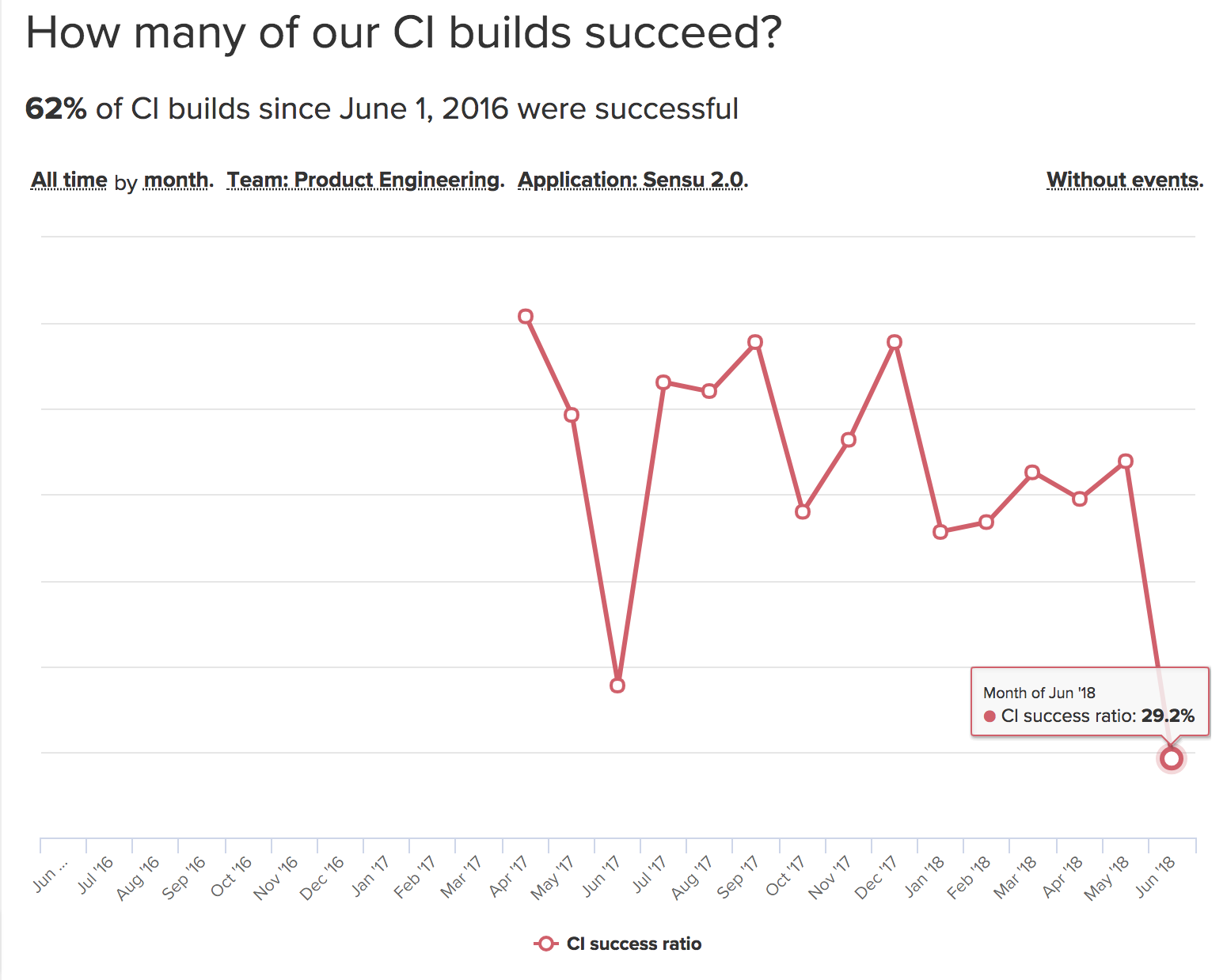
As you can see, we were wrestling with getting a stable CI test suite. And, if we’re having trouble with this, our users will too, since we’re not getting stuff out in a timely fashion. We discovered that our end-to-end testing strategy was brittle, and we had to rework some of our build tests to be more reliable. Again, more on this later.
- User testing, or what I like to call mob QA. You can’t possibly cover every possibility in software testing; you need actual usage in order to uncover bugs.

We got together in a Zoom call, figured out what features we’re trying to test, and determined acceptance criteria. Everyone picked one or two features to test they hadn’t worked on and we set about breaking things left and right. We uncovered some non-major software bugs and — more importantly — deepened our understanding of what the code base and features looked like.
- Load testing. In order to be confident in recommending usage and developing new features, we needed some data points for the types of load our customers would be experiencing.

Our plan was to set up a single VM running sensu-backend in Google Cloud Platform and run a Kubernetes cluster with five agents per pod. We assumed that GKE would autoscale until we had the number of agents we needed (10,000), but in all actuality we ended up load testing GKE! Because we were launching so many pods at once, the API throttled us, so we had to rethink our load-testing strategy. We took the simpler approach of writing a script in Go to spin up 10,000 agents and connected those to a single backend.
These tests helped uncover several interesting bugs, including performance issues (involving an etcd autocompaction bug), a weird UTC timing snafu, and a check scheduling failure. I cover these bugs — and how we fixed them — in detail in my talk.
I’d mentioned earlier that some of our testing revealed gaps (or bugs) in our understanding; I can’t emphasize enough the importance of documentation. I love this quote from Jordan Sissel: “If a new user has a bad time, it’s a bug.” I’ve had many bad times with docs that seemed like bugs but were actually just bad documentation. We wanted to avoid this with Sensu 2.0, and decided to polish our docs for the Beta release. We even created a doc for how to write docs, with recommendations on what a proper guide should include:
- Why you’d want to use this feature
- What it is
- A quick-and-dirty way to get set up
- A reference guide to the feature’s API
A documented guide (for documentation) makes it easier to write consistent stories around a particular feature for how you’d do something. Now, our docs are organized, searchable, and open source — users can contribute when they see issues.
💚 The importance of community (and how we learn from it)
Now that Sensu 2.0 is in the wild, we rely on the Sensu Community to use it and give feedback. We engage with our Community in a number of ways, including our Community Slack, accelerated feedback program, and Community Chats.
We’re also exploring experience reports, which we learned about from the Go community, which include questions like, “How did you expect this feature to work, how did it actually work, and what are you doing with it in your particular environment?”
Our Community continues to inform our decisions and deepen our understanding of how our product is used. Building open source software is ultimately very rewarding — both personally and professionally — and comes with the added benefit of having a large community of users who can help make it better.
Related Posts

Recapping Monitorama 2019 (or, why you should attend Monitorama 2020)
Monitorama is the event of the year if you’re in the monitoring and observability space! It’s an inclusive event for speakers, attendees, and vendors alike to network and learn from each other in a safe, comfortable, and accessible environment.

The best DevOps tools (according to the folks building Sensu)
Here's a roundup of our favorite DevOps tools here at Sensu (no surprise: most of them are open source!).

The power of proposals (and open source culture)
I come from a world where strategy is best kept secret. Whether it be from a company who has a codename for literally everything, or the competitive culture of playing and coaching D1 athletics…

Made with #monitoringlove by SensuTM in Canada 🇨🇦 and the USA 🇺🇸. © 2017-2021 – Privacy Statement – Terms & Conditions