At Sensu Summit 2018, Box.com Sr. Infrastructure SRE Trent Baker told the story of how they migrated over 350,000 Nagios checks to Sensu. In this post, I’ll recap that talk, sharing some info about the infrastructure at Box.com, how they migrated a legacy monitoring system, and what’s next.
 Box.com Sr. Infrastructure SRE Trent Baker at Sensu Summit 2018
Box.com Sr. Infrastructure SRE Trent Baker at Sensu Summit 2018
Site reliability engineering at Box.com
Box.com is an industry-leading platform in content collaboration, with offices in North America, Australia, Asia, and Europe, with over 11 million users. Trent Baker has been at Box for three years; his team designs, builds, and maintains systems such as authentication, configuration management, domain name services, provisioning, and monitoring. The infrastructure SRE team’s mission is to design and build services in a hybrid infrastructure that are highly available, flexible, scalable, secure, and global.
The challenge: scaling monitoring for a globally distributed, growing infrastructure
The Box.com infrastructure is hybrid, consisting of bare metal and both private and public clouds.They have over 16,000 globally distributed compute nodes (and growing!). This includes over 350,000 Nagios objects (hosts, contacts, and services). In order to get visibility into this growing infrastructure, they needed an alerting and monitoring platform that was secure, easy to scale, deploy, and maintain. Unfortunately, Nagios — the legacy monitoring system they had in place — was “anything but those qualities.” They started investigating a more flexible solution.
The pain points of a legacy system
Box.com had deployed a Nagios cluster to every application datacenter, consisting of a single leader and several Nagios followers. They used old versions of Nagios because their highly customized environment (using Puppet as a service discovery tool) wasn’t compatible with the latest versions. Because Nagios was so tightly coupled with Puppet, any changes made to the environment also had to go through Puppet. It took hours and multiple Puppet runs for changes to propagate throughout their infrastructure. Trent cautioned that while this setup was innovative at the time of implementation, businesses should be wary of building a whole technology ecosystem around customization and having it be the foundational basis of your infrastructure. Said another way: it’s difficult to scale.
In an environment producing over 350,000 Nagios objects, the Nagios leader was a huge bottleneck for Box.com. To add insult to injury, the Nagios leader was also a fallover for failed followers — it would run the active checks when the follower wasn’t available.
There were numerous limitations to their Nagios setup:
- The Nagios leader was a single point of failure because it couldn’t be scaled horizontally.
- The Nagios followers were single points of failure because clients had an affinity to a particular follower — if that follower was unavailable, then those checks had to be handled by the leader. This in turn could cause the leader to become overloaded.
- Adding and removing clients, leaders, followers, host groups, and checks was complicated, took hours to perform, and hours to propagate.
- Any misstep in configuration would cause alert storms, increasing the noise to signal ratio in their environment — making on-call engineers extremely unhappy.
- Decommissioning a single server could often cause an empty host group, resulting in configuration errors.
To address these issues, they at first tried upgrading their Nagios instance, but quickly realized there wasn’t a viable path forward. After stabilizing their Nagios environment, they focused their attention on finding their next-generation monitoring system.
Enter Sensu
The next monitoring solution for the Box.com SRE team needed to:
- Be able to monitor a hybrid cloud environment
- Contain no single points of failure
- Be secure, easily deployed, scaled, and maintained
- Integrate with PagerDuty, Slack, email, JIRA, and Puppet
- Most importantly, use existing Nagios plugins
After working with the Sensu team, Box.com set up their architecture like so:
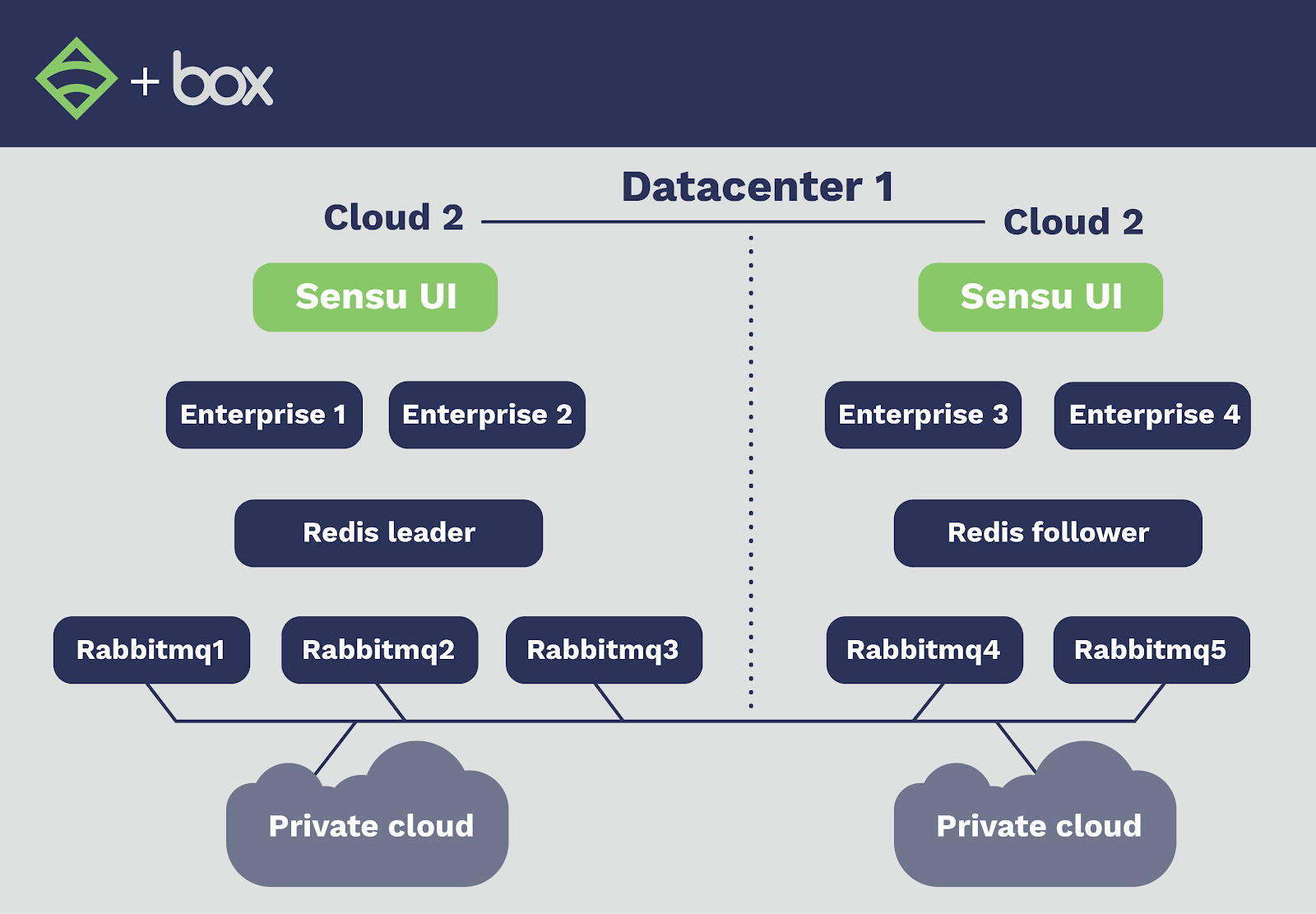
Each of their application datacenters is equipped with two physical clouds that act as a single, logical cloud. They deployed a Sensu cluster to each cloud, distributing the Sensu components as evenly as possible over different racks and hypervisors to increase their availability. There are two Sensu dashboard servers in each physical cloud, each with a healthcheck to announce their availability for connections. If either of the dashboards fail, users will get routed to the closest dashboard server — a design not so much for load balancing as it is for availability.
They installed Redis sentinel on each of the RabbitMQ servers to monitor Redis’ availability and manage failover between the Redis leader and follower. While they’d had concerns around split brain issues (deploying RabbitMQ and Redis across two physical clouds), advantages in terms of availability increased have far outweighed the risk. In turn, the hosts in the private cloud connect to RabbitMQ servers via a secure connection. Now, they don’t have single points of failure, can scale the configuration horizontally, and the system is easy to deploy and manage.
The migration
As with many implementations, there were some initial challenges — as Trent noted, the team had what they thought was a green field, but was actually a bit brown (“a little rocky, with some spatters of tree stumps”). In addition to having a customized Nagios setup, they had also customized their RabbitMQ and Redis modules. They wanted their move to Sensu to take advantage of industry best practices, and leverage community knowledge by using Puppet Forge modules. They spent a few weeks renaming custom modules, upgrading dependent modules, and modifying Puppet code to eventually turn that brown field green. From there they were able to deploy Sensu and the RabbitMQ and Redis Forge modules to the Puppet repository. In keeping with industry best practices, they went with Puppet roles and profiles. Here’s a list of Puppet profiles that do the heavy lifting:
They used these profiles to establish the framework to make migration easier, but also to help other teams adopt Sensu. In order to encourage adoption, they made things as simple as possible for users to migrate their checks over to the new environment.
Here’s an example to illustrate one of the Puppet profiles they use, making use of Hiera key-pairs to populate Sensu contacts for PagerDuty, email, and JIRA.
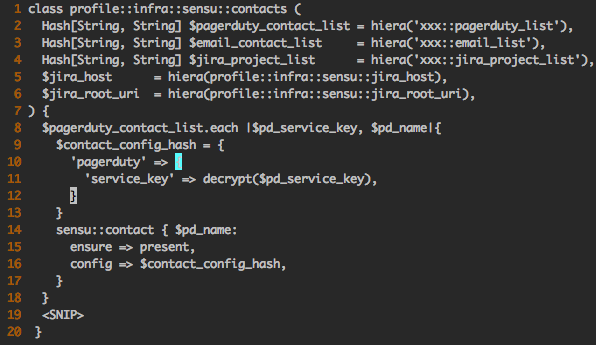
Because Box.com has a distributed environment for service owners (who are also really good at managing their services), users don’t necessarily need to know Sensu, Puppet, or JSON to add context to their checks. They store their Sensu contact details in Hiera yaml configs, and the Puppet profiles propagate the correct settings for each service.
The next step in the migration was a mapping all the Nagios classes to Sensu classes: nagios::client::add_to_hostgroup and nagios::magic::add_to_hostgroup.
As you can see below, both mapped to sensu::subscription, while nagios::object::{service|hostgroup|command} mapped to sensu::check.
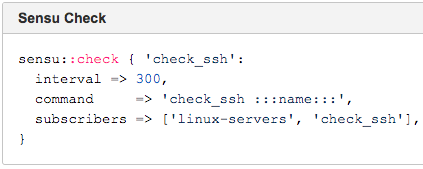
Most of complexity for the service discovery mechanisms they were using in Puppet was in the nagios::magic class. Although this mapping goes to sensu:subscription, they deleted that code to remove the dependency on service discovery. As far as check definitions are concerned, there were three classes that mapped to the Sensu check: the Nagios object service, host group, and command. Because three Nagios classes now map to one Sensu check, it’s now easier for Box.com to maintain their environment and their Puppet code is cleaner. Because the overhead for migration and adding checks was a lot lower, adoption improved.
Trent also discussed how they migrated aggregate checks — including mapping Nagios checks to Sensu checks, and a wrapper they wrote around the Sensu subscription call that defined and configured the custom hash. For a deeper dive, check out his talk.
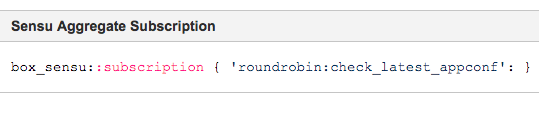
Before Sensu, it was rather onerous to have an aggregate check subscription. Now, here’s what the Box.com team inputs into Puppet:
The results + what’s next
By the end, they’d migrated approximately 1,250 Nagios checks running over 16,000 hosts for their production environment. They also have a Sensu cluster for dev and staging, which has about 3,000 servers. Ultimately, the Box.com team found Sensu “very easy to deploy.” They’ve deployed Sensu to five different datacenters and growing, initially running their clusters on one cloud, which only had two enterprise servers, three RabbitMQ servers, and one dashboard server. They’ve scaled Sensu significantly, easily growing horizontally (as seen in the above architecture diagram). The team also found that the Sensu environment increased availability and their administration over it.
Going forward, the Box.com team plans to:
- Go deeper with Sensu integrations, using the Wavefront integration in Sensu Enterprise to help migrate their metrics checks (and using Sensu as a pipeline into Wavefront) as well as implement Sensu’s single sign on integration.
- Deepen their Stackstorm instance and use Sensu as a trigger to do autoremediation.
- Do cross-datacenter monitoring so they can “monitor the monitor.” As Trent put it, “It doesn’t do any good to monitor the thing that you’re actually inside. You need to take the infrastructure outside of your cloud and monitor across datacenters.”
- See what’s new with Sensu Go.
Watch the video of Trent’s talk below, and stay tuned — we’ll continue to recap talks from Sensu Summit.
Looking for Nagios alternatives? Check out these resources on running your existing Nagios plugins in Sensu.
Related Posts

On the merits of pubsub & workflows (or, why Sensu over Nagios)
In this Sensu Community post, we hear from Sr. Insights Engineer Jason Anderson on why Willis Towers Watson chose Sensu over Nagios, including his learnings and favorite features.
Community roundup: making the switch from Nagios to Sensu
Love it or hate it, Nagios played a critical role in establishing monitoring as a practice and helped train a generation of operators who required visibility into their systems.
Migrating to Sensu, as told by a Nagios refugee
One of our favorite stories at Sensu is hearing how our customers are using, repurposing, and even replacing their Nagios setup.

Made with #monitoringlove by SensuTM in Canada 🇨🇦 and the USA 🇺🇸. © 2017-2021 – Privacy Statement – Terms & Conditions